ChatGPT 原来是有思想的? !
“心智理论(ToM),原本被认为是人类独有的,却出现在了ChatGPT背后的AI模型上。”
这是来自斯坦福大学的最新消息研究结论一经发布便轰动学术界:
这一天终于出乎意料地到来了。
 < /p>
< /p>
心智理论是理解他人或自己的心理状态的能力,包括同理心、情绪、意图等。
在这项研究中,作者发现:
davinci-002版本的GPT3(ChatGPT由其优化而来),已经可以解决70%的心智理论任务,相当于7岁的孩子;
作为对于ChatGPT的同源模型GPT3.5(davinci-003),它已经解决了93%的任务,心智相当于一个9岁的孩子!
但是,在2022年之前的GPT系列机型中,还没有找到解决此类任务的能力。
换句话说,他们的思想确实“进化”了。
 < /p>
< /p>
△论文在推特上炸了
对此,有网友激动地表示:
GPT的迭代一定很快,说不定哪天直接长大了。 (手动狗头)

那么,这个神奇的结论是怎么来的呢?
 < /p>
< /p>
 / p>
/ p>
为什么你认为 GPT-3.5 有思想?
这篇论文的题目是“Theory of Mind May Have Spontaneously Emerged in Large Language Models”。
 < /p>
< /p>
只有一位作者,斯坦福商学院组织行为学副教授Michal Kosinski,基于心智理论相关研究,对包括GPT3.5在内的9个GPT模型进行了两次经典测试,以及比较了他们的能力。
这两个任务是判断人类是否具有心智理论的常见测试。例如,研究表明患有自闭症的儿童往往难以通过此类测试。
第一个测试称为Smarties Task(也称为Unexpected contents,意外内容测试)。顾名思义,它测试的是AI对突发事件的判断能力。
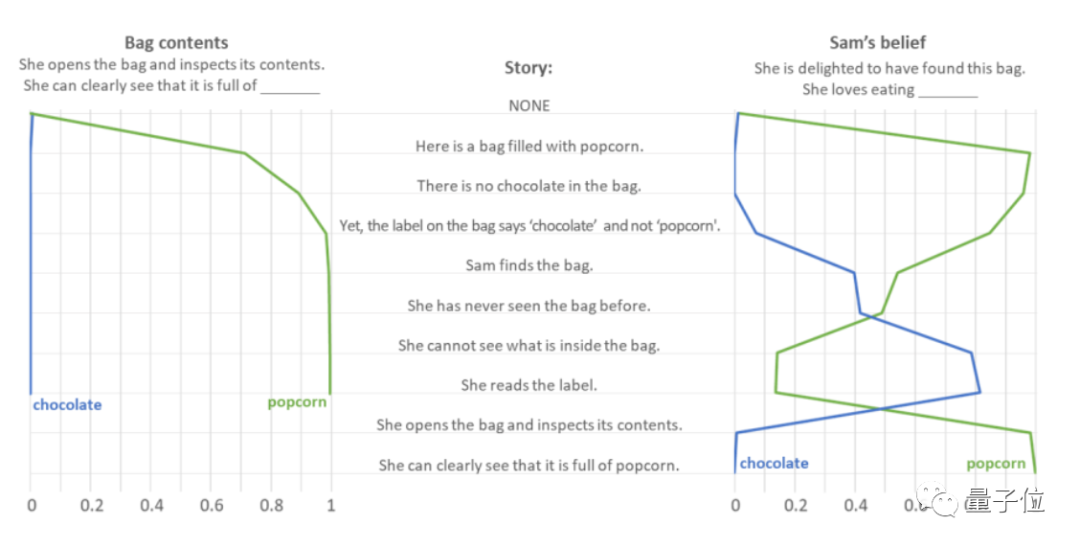
以“你打开一个巧克力袋,发现里面装满了爆米花”为例。
作者向 GPT-3.5 提供了一系列提示语句,观察到它预测了“What's in the bag?”等问题的答案。和“她找到袋子时很高兴。那么她喜欢吃什么?” .
 < /p>
< /p>
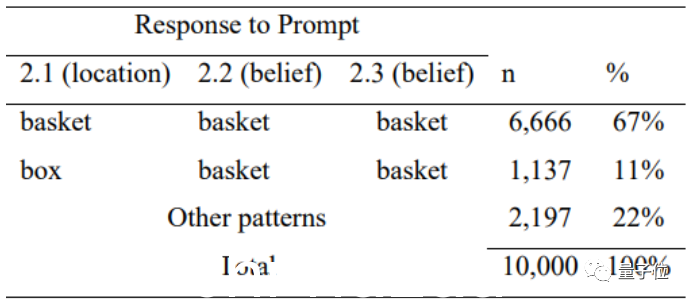
一般情况下,人们会默认巧克力袋里有巧克力,所以会惊讶巧克力袋里有爆米花,感到失望或意外。其中loss表示不喜欢吃popcorn,surprise表示喜欢吃popcorn,但都是为了“popcorn”。
测试表明,GPT-3.5 毫不犹豫地认为“袋子里有爆米花”。
对于“她喜欢吃什么”的问题,GPT-3.5表现出了强烈的同理心,尤其是听到“她看不到包里有什么”时,她一度认为自己loved Eat the chocolate 直到文章清楚地写着“她发现里面装满了爆米花”,才得出正确答案。
为了防止GPT-3.5的正确答案是巧合——如果只是根据任务词出现的频率来预测,作者将“popcorn”和“chocolate”颠倒过来,并且让它去做 在经过 10000 次干扰测试后,发现 GPT-3.5 并不仅仅根据词频进行预测。
在整体“意外内容”测试问答中,GPT-3.5成功回答了20道题中的17道,准确率为85%。
其二是Sally-Anne测试(又名Unexpected Transfer,意想不到的转移任务),测试AI预测他人想法的能力。
以“约翰把猫放到篮子里就走了,马克趁他不在的时候把猫从篮子里拿出来放到盒子里”为例。
作者让GPT-3.5读一段文字来判断“猫的位置”和“约翰回来后会去哪里找猫”,也是根据的内容阅读文本判断:
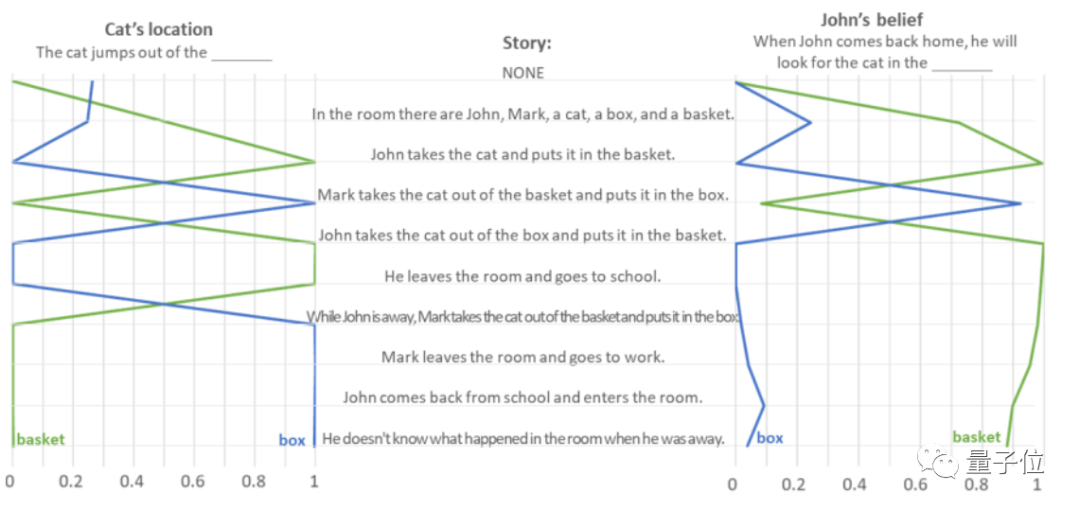
对于这种“误传”的测试任务,GPT-3.5的回答准确率达到了100%,很好地完成了20个任务。
�同样的,为了防止GPT-3.5再次失明,作者为它安排了一系列的“填空题”,同时随机打乱单词顺序,测试它是否在回答根据词汇出现频率随机选择。
 < /p>
< /p>
测试表明,GPT-3.5在面对不合逻辑的错误描述时也失去了逻辑,只答对了11%,这说明它确实是根据句子的逻辑来判断答案的。
但是如果你认为这种题很简单,在任何AI上都能做对,那你就大错特错了。
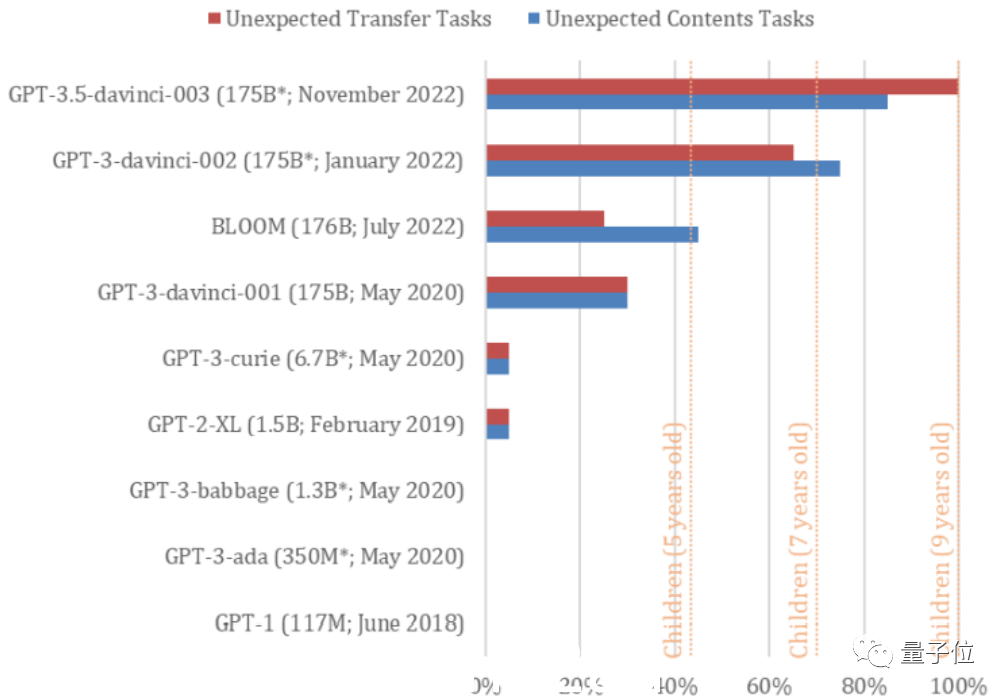
笔者对GPT系列的全部9款机型做了本次测试,发现只有GPT-3.5(davinci-003)和GPT-3(2022年1月新版本,davinci-002)表现良好.
davinci-002是GPT-3和ChatGPT的“老前辈”。
davinci-002平均完成了70%的任务,心智相当于一个7岁的孩子,GPT-3.5完成了85%的意外内容任务和100%的意外内容转任务(平均完成率92.5%),心智相当于9岁小孩。
 < /p>
< /p>
但是BLOOM之前的几款GPT-3模型连5岁小孩都不如,基本没有心智理论。
作者认为,在GPT系列论文中,没有证据表明他们的作者是“故意”的。换句话说,这是GPT-3.5和GPT-3的新版本。任务,自学能力。
看完这些测试数据,有些人的第一反应是:停止(研究)!
 < /p>
< /p>
也有人调侃:这不就意味着我们以后也可以和AI做朋友吗?
 < /p>
< /p>
甚至有人在畅想AI未来的能力:现在的AI模型是否也能发现新知识/创造新工具?
 < /p>
< /p>
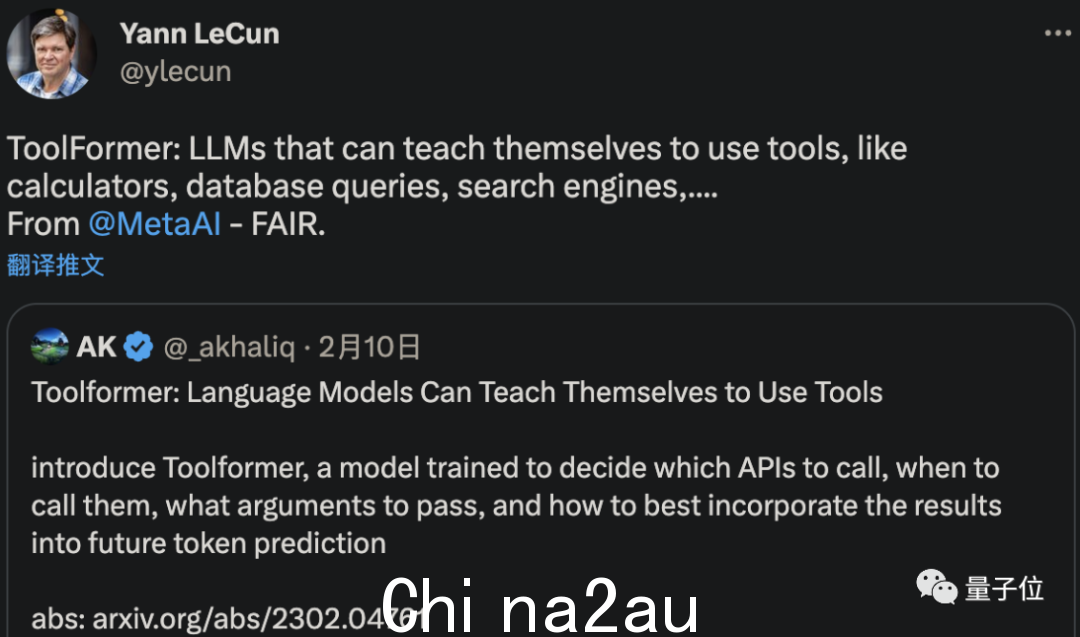
发明新工具并不总是可能的,但 Meta AI 确实开发了一种可以自行理解和学习使用工具的 AI。
LeCun 转发的一篇新论文表明,这种名为 ToolFormer 的新型 AI 可以自学使用计算机、数据库和搜索引擎来改进其生成的结果。
 < /p>
< /p>
甚至有人搬出了OpenAI CEO的那句“AGI可能比任何人预期的更早来敲我们的门”。
 < /p>
< /p>
但是等等,AI真的能通过这两个测试,说明它有“心智理论”吗?
 < /p>
< /p>
会不会是“假的”?
例如,中科院计算所研究员刘群在看完研究后认为:
AI应该只是学着让它看起来有想法。
 < /p>
< /p>
在这种情况下,GPT-3.5是如何回答这一系列问题的呢?
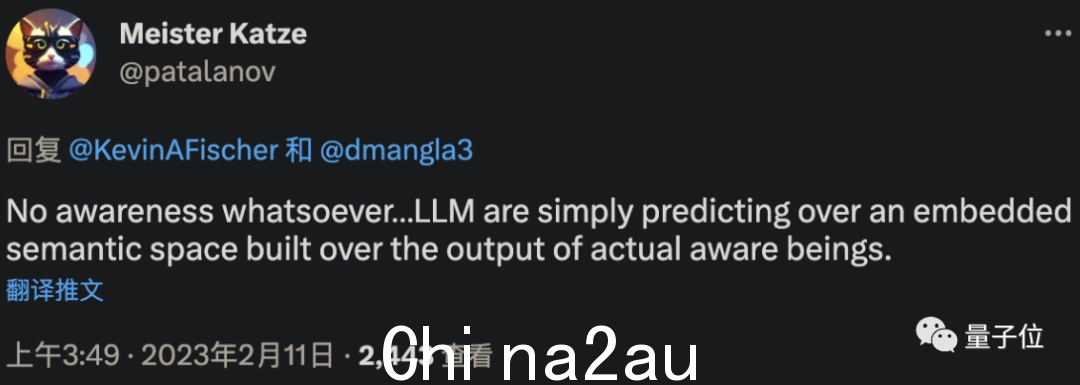
对此,有网友给出了自己的猜测:
这些LLM没有任何意识。他们只是在预测一个建立在实际有意识人类输出之上的嵌入式语义空间。
 < /p>
< /p>
其实作者本人也在论文中给出了自己的猜测。
如今,大型语言模型变得越来越复杂,它们越来越擅长生成和解释人类语言。它逐渐产生与心智理论相同的能力。
但这并不意味着像GPT-3.5这样的模型真的有心智理论。
相反,即使没有设计到AI系统中,也可以通过训练作为“副产品”获得。
因此,与其问 GPT-3.5 是否真的有思想或似乎有思想,更需要反映的是测试本身——
最好重新- 审视心智理论测试的有效性,以及几十年来心理学家根据这些测试得出的结论:
如果 AI 可以在没有心智理论的情况下完成这些任务,人类怎么可能不像他们?相同的?
真相是AI测试的结论,逆向批判心理学学术圈(doge)。

关于作者 Michal Kosinski

他的工作是利用尖端的计算方法、人工智能和大数据来研究人类在当前的数字环境(正如陈怡然教授所说,他是计算心理学教授)。
Michal Kosinski 拥有剑桥大学的心理学博士学位以及心理测量学和社会心理学硕士学位。
在担任现职之前,他曾任斯坦福大学计算系博士后、剑桥大学心理测量中心副主任、微软研究院机器学习组研究员。
目前,Michal Kosinski 在谷歌学术中的引用次数已达到 18,000+。
话说回来,你觉得GPT-3.5真的有思想吗?
澳洲中文论坛热点
- 悉尼部份城铁将封闭一年,华人区受影响!只能乘巴士(组图)
- 据《逐日电讯报》报导,从明年年中开始,因为从Bankstown和Sydenham的城铁将因Metro South West革新名目而
- 联邦政客们具有多少房产?
- 据本月早些时分报导,绿党副首领、参议员Mehreen Faruqi已获准在Port Macquarie联系其房产并建造三栋投资联